
Literature Survey on 3D Reconstruction of a Single Human’s Pose and Shape
Published:
Abstract
Human digitization is an active and growing research topic with its sub-branches that have unique sets of problems and use-cases of application. Approaches including, but not limited to parametric-model based, model-free based, real- time, offline, single and multi-camera are all unique directions at which research is being conducted. This paper aims to outline the field as a whole and provide an overview of the current state-of- the-art as well as give an insight into older technology that has set the path for the field. Modern approaches leverage deep learning to estimate human models with a fine level of detail for clothing, facial features and can prove to be scene-aware by modelling also objects that are a focus of the human subject’s interaction. The survey concludes that the technological holy-grail has still not been achieved and with the increased use and accessibility of Virtual/Augmented Reality, human digitization will become more and more relevant in use cases such as broadcasting, teleconferencing, avatar generation and others.
Introduction
Digital reconstruction of humans is an emerging field within computer graphics and is made possible given the advantages of modern computational power, advances in deep learning. Given the progress of immersive AR/VR media, digital reconstruction of humans is relevant for fields such as AR/VR conferencing, industrial training, avatar generation and others. This paper focuses on surveying the recent works within the field using similar terminology by discerning model-based and model-free fields, with a further in-depth review of model-free single-view and multi-view systems, see Figure 1.
Model-Free subfield refers to any framework that estimates a human mesh through regression methods that directly, or with certain pre-processing steps, maps input image to body joint coordinates or a 3D mesh. Whereas model-based subfield, in this report, will refer to any frameworks that output a mutable template mesh with a set of tweakable parameters, or frameworks that build on such parametric models.
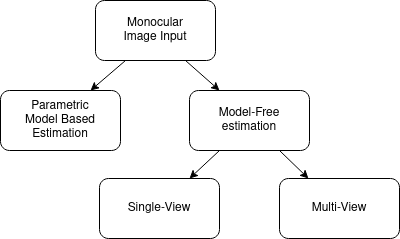
Figure 1. Structured overview of human pose estimation research areas reviewed in this blog post.
Model-Based Reconstruction
Reconstructing a human mesh through using parametric models as starting templates [2, 3, 4, 5, 6] can prove be an efficient technique at replicating the pose and the body shape of the given input vector [7, 8, 9, 10, 11, 12] [13, 14]. In essence, parametric modelling aims to describe a given human body using parameters specific to pose and body features that are normally derived during estimation model training. This process normally is data-driven as it involves processing human body data-sets for deriving the features and deciding how they should be mapped to the template mesh [15]. This means that any prediction algorithms that make use of model-based reconstruction are relieved from the burden of estimating a full mesh from scratch, thus allowing the solution to focus mainly on parameter estimation. When compared to approaches such as photogrammetry scans or from-scratch mesh estimation, using parametric bodies is a more robust approach because it is less susceptible to noise, gaps or missing regions that may occur during scans or from-scratch mesh generation [16, 17]. The downside of the approach is that the result is limited to the quality and flexibility of the parametric model.
Shape Completion and ANimation for PEople (SCAPE)
The SCAPE model is one of the first significant works in the parametric human model area [2]. SCAPE uses a Correlated Correspondence algorithm to correlate inputs from CAESAR[18] dataset of human scans to a reference mesh. Afterwards, an articulated skeleton is recovered with 16 parts and the pose is represented through relative joint rotations, this allows for rigid bone movement. The model also deforms the body shape independently of the pose using a custom set of linear transformation matrix and is also able to model facial features, see Figures 9-10.
Skinned Multi-Person Linear Model (SMPL)
The SMPL model [3] proves to be the de-facto standard that has been used for pose and body shape reconstructions in the recent years within academic and industrial communities [10, 7, 8, 9, 11, 4]. Similarly to SCAPE, the SMPL model also handles pose and shape estimation in a decoupled manner. SMPL uses vertex-based skinning, has a higher output resolution, runs about six times faster and generalizes better to new shapes when compared to BlendSCAPE, which is a continuation of SCAPE [19]. Due to the nature of SMPLs dense blend shapes, a rotation in a single part of the body can influence any vertex on the mesh. This helps the model to generalize better to more complex shapes by replicating the natural deformations of muscles/soft-tissue when in complex poses SMPL is designed with industrial use as a priority, hence it directly integrates with modern production pipelines.
Sparse Trained Articulated Human Body Regressor (STAR)
STAR is a recently published parametric model, that claims superiority over the SMPL model [4]. When compared to SMPL, the STAR model has a parameter reduction of about 20% while providing more realistic deformation and better generalization when trained on the same dataset - CAESAR. Contrary to SMPL, STAR also accounts for shape-dependent deformations influenced by input’s body pose and body- mass index (BMI), because people with different body shapes deform differently. The STAR models pose as a set of local blendshape functions where each joint of the body influences a sparse subset of vertices. As depicted in Figure 2, during a sparse pose estimation, a mesh is fitted to a person, the arrows are pointing to joint locations and the heatmap indicates topological changes only in local-region vertices. After the sparse pose estimation, a body shape is then estimated as a second step, which then further again affects the pose, this is done to simulate different poses depending on BMI, see Figure 3.
![]()
Figure 2. Pose-Dependant Body Deformation. Image from [4]
![]()
Figure 3. Example of STAR model applying Body-Mass Index based shape deformation; High-BMI (Top); Low-BMI(Bottom). Image from [4]
Implicit Generative Models (imGHUM)
The imGHUM model is an innovative approach in the field as the authors claim it to be the first holistic generative model that can represent a 3D human shape and an articulated pose [6]. It is different from all previously surveyed models in that it does not use an explicit template of a mesh but rather estimates it implicitly using mathematical functions.
The model uses two neural networks with varied resolutions to estimate the human mesh. The lower resolution model decodes a signed distance function (SDF) S for a latent code α at an arbitrary point p that represents the global features of the mesh. To better represent the higher frequency information in hands and face, the mesh is split into 4 distinct regions, face, two hands and rest of the body for which a higher resolution network captures local details that also generalizes to inclusive body shapes, see Figures 13-14. The higher detail model allows for a better representation of hair, clothing, fingers as residuals. To improve the high-frequency information learning, the samples of a mesh are estimated using an SDF and encoded using Fourier mapping [20]. A similar approach of splitting the estimation problem into chunks is used in other works
![]()
Figure. 4. Overview of imGHUM performance. From left to right. Single Network w/ Fourier mapping; Multi-Network; Ground-truth. Note the fine detail modeling of facial features and fingers. Image from [6].
Model-Free Reconstruction
Reconstructing a human mesh without any pre-defined parametric templates is also an active research field. Contrary to model-based reconstruction, the model-free based approach has an additional burden of also deriving and rendering the mesh itself. Different research teams have published their solutions that derive a human mesh from a single camera feed in real-time [21, 22, 23, 24].
Work has also been done on off-line pose estimation [16, 17, 25]. Works on multi-camera setups have also been done [26, 27]. All of the frameworks leverage a data-driven approach and deep learning to perform the estimations.
Single Camera Real-Time Frameworks
Single-camera real-time estimation is an incredibly chal- lenging problem because of very thought-through and processing-efficient solutions that need to be deployed to achieve quick rendering, natural occlusion and solve the depth ambiguity. Research in this area naturally is developing as a lot of the methods described in this paragraph rely on knowledge retrieved from earlier off-line human mesh reconstruction approaches, while adding additional optimizations suited to satisfy the real-time constraints.
Monocular Real-Time Volumetric Performance Capture
One of the first works towards single-camera real-time estima- tion has been published in 2020 [21]. It is based on the PIFu publication [28] with the addition of introducing modifications to the PIFu framework. The authors admit that while PIFu performs well at reconstructing human models with the level of detail that would be unfeasible using voxel-based approaches, they claim that rendering a mesh at resolution 2563 takes tens of seconds per object on their hardware. Thus for real- time applications, the authors’ approach achieves the same resolution and robustness in 15FPS by leveraging some of the real-time constraints. The authors process a continuous stream of RGB images individually. Firstly, they separate the subject from the background and afterwards it is fed into their custom modified PIFu framework.
The paper contributes an improved surface localization algorithm that moves from brute-force (original PIFu) to a logarithmic computational complexity [21], and a mesh-node culling algorithm based on the camera view. The original PIFu paper localizes the surface by evaluating all points within a bounding box, whereas the authors’ contribution uses an improved model that evaluates points only in close proximity to the actual surface. Afterwards, the surface extraction is performed by culling all shadow mesh nodes from a given camera perspective X, this essentially create an illusion of a 3D mesh. Secondly, a texture is directly inferred from PIFu.
While this approach would work well for virtual conferences because of a single static viewpoint, it would become more demanding to scale in interactive/immersive 3D contexts because a mesh would need to be rendered from every perspective that a participant of the experience is viewing it, as opposed of rendering it once as a full 3D mesh.
Multi-Camera Real-Time Frameworks
With the introduction of more cameras, comes more raw data of the scene. The increased amount of raw data naturally provides an advantage over single-camera based approaches although, depending on the setup and approach, it can make the technology less accessible. Certain publications describe high-end volumetric capture systems with dense camera rigs, laboratory-like light conditions that eventually provide impres- sive results, although normally such systems are not accessible to consumers and require access to specialized studios [29] [30]. This section of the report surveys only multi-camera rigs that are compatible with consumer-grade equipment and use sparse camera rigs.
Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors:
A recent study that claims to be the first real-time volumetric capture rig that uses synchronized RGB-D cameras combined with volumetric fusion, which is essentially merging multiple inputs into a single 3D reconstruction. Afterwards, the fused 3D geometry is processed with deep implicit functions that use RGBD sensors for classifying query point locations in or outside a shape that help preserve higher frequency details[23].
The novel volumetric fusion Dynamic Sliding Fusion (DSF) is the first step of the pipeline framework and processes the input data in chunks of 3 frames. The input to the framework is delayed by 1 frame t for the purpose of windowed processing. Only three frames t-1; t; t+1 are fused to prevent error accu- mulation over time, and surface tracking is only performed on the succeeding frame t+1.
The DSF is topology-aware meaning that objects with semantic relevance to the human subject are not discarded. The framework makes use of off-loading computation to a GPU and authors claim to output a mesh estimation with a resolution of 2563 at 25FPS although they do not state the hardware specs they had available.
NeuralHumanFVV: Real-Time Neural Volumetric Human Performance Rendering using RGB Cameras:
Mesh reconstruction using RGB cameras and a data-driven approach for performing the estimation is a more lightweight solution than RGB-D cameras in the sense that it is, even more, cheaper and more accessible to reproduce the results [24]. Similarly, how other off-line approaches use a single RGB input [28] [16], they suffer from self-occlusion and do not generalize well to complex poses. The previously stated challenges are the motivation for this publication, which also aims to achieve real-time performance.
The approach leverages a six RGB camera cluster surround- ing the subject that derives the geometry prior, which is then fed into Multi-View Implicit Function (MVIFu) that is based on modifying the pixel-aligned implicit function (PIFu) [16] [28]. This is essentially a two-stage approach that does a coarse-to-fine estimation that uses Shape-From-Silhouette [31] framework as the coarse estimator and MVIFu as the fine level estimator. The finer details are derived by comparing two of the estimated Z coordinate values when from the coarse and fine geometry, the final Z coordinate is an average of both. Afterwards, a neural network estimates the displacement error, to prevent over-smoothed results and to retain high-frequency information. Computational power is saved by predicting the geometry that is only visible from the camera perspective, thus skipping the processing of occluded sections.
To output even more fine-detailed geometry, texture and depth maps are also estimated and encoded by processing adjacent input views. For real-time purposes the depth map is generated at 256x256 resolution and then upsampled to 1k resolution using a boundary-aware scheme to prevent zigzag artifact caused by depth ambiguity between multiple input views, see Figure 5. The final speed of the system is 12 FPS when running an experiment on a PC with CPU 3.7 GHz Intel i7-8700k 32GB RAM, and Nvidia GeForce RTX3090 GPU. The system is aware of topology changes such as clothes and props (basketball, bag).
![]()
Figure 5. Comparison of depth map upsampling without (left) boundary-aware scheme and with (right) [6].
Single-Camera Off-Line Frameworks
PIFuHD: Multi-Level Pixel-Aligned Implicit Function
uilds upon the predecessor paper [28] by adding a multi- level architecture that observes input with two different levels of granularity [16]. Compared to previous related works [28] [12], PIFuHD paper authors argue that resolution at which the 3D reconstruction is performed is not sufficient to recover high-frequency details such as facial features, clothing wrinkles or fingers, hence this is the main motivation for the contribution.
The framework leverages 1k images by first encoding holistic coarse geometrical information that is then propagated to a higher fidelity high-detail encoding module. It uses a data- driven approach to train a neural network using 3D people dataset [32]. The network predicts binary occupancy that determines whether 3D points are inside or outside the human body in continuous camera space.
Firstly, depth maps for the front and back sides of a person are predicted and used as additional features to guide both of the estimation modules. The coarse-detail module uses a downsampled image from 1k to 512x512 that produces backbone features at 128x128 resolution. Afterwards, the fine-detail module uses the coarse-detail module’s extracted features in addition to the depth map as guidance to prevent artifacts and to leverage the original 1k image to produce backbone image features at 512x512 resolution. See Figure 6 for a pipeline overview and Figure 7 for an overview of fine- detail module comparison with and without low-detail context.
![]()
Figure 6. Overview of PIFuHD pipeline architecture. Image from [16]
![]()
Figure 7. Comparison of fine-module’s mesh reconstruction without(B) coarse module’s features as input and with (C) [16]
End-to-End Human Pose and Mesh Reconstruction with Transformers
The framework [27] is different to many of the previously surveyed approaches because it leverages two neural network modules that use Convolutional Neural Net- work and a modified multi-layer Transformer Encoder [33] as the underlying architectures for the framework. The authors claim the Transformer to be superior for mapping vertex- vertex correlations between non-local regions of an input body, as suggested to be important [34]. Learning the long-range vertex-vertex interactions is important for better reconstruction of the body shape when in complex poses, as well as it is more robust to self-occlusion. The framework is designed to generalize also to other types of 3D meshes, i.e. hands.
The framework uses a 224x224 image as input and predicts a set of joints and mesh vertices. The CNN module extracts image features and the transformer estimates 3D coordinates of the body joints and mesh vertices. To output the 3D coordinates, the authors modify the Transformer to include a dimensionality reduction between the hidden embeddings for all transformer layers that end with a 3-dimensional output, see Figure 8.
![]()
Figure 8. Transformer Encoder architecture. Image from [27]
The framework heavily benefits from Masked Vertex Mod- eling, a technique inspired by natural language processing. Masked Vertex Modelling essentially means that certain vertex queries are masked at random and the network architecture is forced to infer it from other vertices and joints that are relevant, disregarding their distance from the query point. This essentially simulates occlusion.
During training, an L1 loss function is used to minimize prediction and ground-truth errors. The model receives an RGB image, ground-truth 3D coordinates of mesh vertices, ground-truth 3D coordinates of the body joints and ground- truth 2D coordinates of the body joints.
Results
An overview of output produced by each mesh generation approach is presented with qualitative data in Figures 9 - 20 of the discussed mesh reconstruction approaches is presented as well as further details on the trained datasets.
Figures 9-10 depict results from SCAPE parametric model. The methodology uses a data-driven approach for learning features from 3D scans and then estimating novel poses. Training data was a mixture of CAESAR dataset, and own custom scans consisting of two additional datasets. Pose estimation was trained on scans of 70 varied poses of a single person, whereas body-shape estimation was trained on 37 scans of people in similar poses.
![]()
Figure 9. Results from SCAPE reconstruction, notice the muscle deformation modeling. Image from [2].
![]()
Figure 10. CAPE body pose and shape estimation, facial features were masked out by the original authors for anonymity purposes. Image from [2].
The results for SMPL estimation are generated from a model trained on multi-pose dataset consisting of 1786 datapoints made out of 40 individuals in different poses (891 poses of 20 females, 895 poses of 20 males. For shape estimation, CAESAR dataset is used with 1700 males and 2100 females. Figure 11 depict the SMPL model’s estimation.
![]()
Figure 11. Comparison of SMPL-LinearBlendSkinning(red); SMPL-DoubleQuaternionBlendSkinning(Orange); Registered Mesh (dark gray) and scanned ground-truth (light gray). Note the shape deformation around calves, thighs and triceps. Image from [3]
The STAR model was trained on the same dataset as SMPL although the authors argue that since the dataset comes from the 1990s, it doesn’t fully represent people’s shapes nowadays, hence they extend the training dataset with SizeUSA[35] that provides over 10’000 additional data points (approx 2.8k males and approx. 6.4k females). See Figure 12 for results on STAR estimation.
![]()
Figure 12. Qualitative comparison of ground-truth (blue) vs SMPL (brown) vs STAR (white). Note the improved shape of STAR over SMPL’s spikes around the outer edges of the models; Image from [4]
The imGHUM uses 75000 randomly sampled datapoints from H36M[36] and CMU MoCap[37] datasets as well as 35k additional human scans. See Figure 14.
Monocular Real-Time Volumetric Performance capture used RenderPeople dataset of 466 static scans, as well as extending it with synthetic data generated by taking additional 167 rigged models from RenderPeople and applying 32 animations from Mixamo[38] and randomly selecting 3 frames from each animation. The final number of datapoints was 466 + 167 × 32 × 3 = 16,498. Figure 15 depicts qualitative results of ground- truth vs rendered and textured mesh.
![]()
Figure 13. Example of imGHUM results. Depicts modeling of inclusive body shapes. Image from [6]
![]()
Figure 14. Example of imGHUM results with high frequency estimation. Image from [6].
![]()
Figure 15. Results of RT Monocular Volumetric Rendering. Input image (top) and generated mesh + textured (bottom). Observe the artifacts around hands, lack of finger reconstruction, feet deformation. Image from [21]
The results for parametric based model estimation show that SMPL model estimates the general pose of the ground- truth, although it lacks the detailed resolution and has artifacts around knees, elbows and triceps. The STAR model demon- strates a feature that SMPL does not account for, which is the body-shape topology affecting the pose estimation through BMI information. The imGHUM output demonstrates fine details of clothing wrinkles, facial features and fingers, that all previous parametric-based models fail to achieve.
Figure 16 shows results of the Function4D publication’s model that was trained on a custom dataset of 500 scans from which images were derived of additional augmented data that was generated by rotating the scans across Yaw, applying ran- dom shifts and generating 60 views with a 512x512 resolution per scan.
![]()
Figure 16. Function4D Results. Dancing girl. Generated mesh (top), textured mesh (bottom). Observe the lack of finger details; floating vertices around hair; Distorted hand (2nd to left). Image from [23].
Figure 17 shows qualitative results of the Neural Human FVV. The model was trained on Twindom [39] with 1820 datapoints and additional augmentations were performed by rigging the 3D models to add more challenging poses for better generalization.
![]()
Figure 17. Neural Human FVV results. Observe the topology awareness (basketball, rucksack); Distorted hand (spiderman; far-left image); pixelated outter edges; Distorted hoodie (basketball player, middle image). Image from [24].
Figure 20 depicts qualitative results from PIFuHD that used RenderPeople[32] dataset that was split into 450 datapoints for training and 50 for testing.
Figure 19 depicts human pose and shape reconstruction using Transformers and Figure 18 depicts the same framework generalizing specifically to hand reconstruction. The frame- work leverages 2D and 3D datasets. Human3.6M dataset with artificially created pseudo labels. 3DPW dataset with 2D and 3D annotations consisting of 22k images, an outdoor-image dataset UP-3D with 7k images, MuCo-3DHP synthesized dataset based on MPI-INF-3DHP with 200k training images, COCO with 2D annotations, MPII 2D pose with 14k images, FreiHAND 3D hand dataset with training datapoints of 130k images. For an overview of all surveyed material see Table I.
![]()
![]()
Figure 18. Results of human hand reconstruction with Transformers. Observe the occlusion modelling (second-bottom); Artifacts around the thumb (second- top and middle); Image from [27].
![]()
Figure 19. Results of human shape and pose reconstruction with Transformers. Notice the lack of topology awareness (missing sword and guitar); lack of facial feature modelling; incorrect head orientation (top and middle images); Artifacts around foot and hand orientations (top and middle accordingly). Image from [27].
![]()
Figure 20. PIFuHD Results. Note the homogeneous hair and missing shoe heel (bottom-left); Inconsistent ear rendering (bottom-right); lack of resolution around shoes and pants, inconsistent foot orientation (top-right); Inconsistent thumb and hair representation (top-left). Image from [16].
Discussion
The results show distinctions between the quality of output in all estimation methods as well as an upward trend over time of quality improvement and diversity of methodologies. It is important to note that real-time mesh renderings do not generate a full mesh per-se but rather depict an illusion of the mesh based on an arbitrary position from which the scene is observed. All of the methodology sub-categories are discussed separately while providing particular use-cases and contexts at which they would shine the best.
Model-Based
Model-based replication has been a research topic for decades with the first significant state-of-the-art being set in
- The SCAPE model is able to replicate the pose, body shape and supposedly facial expressions although the original publication had censored the facial features for anonymity purposes therefore which made it hard to get a true overview for replicating that particular feature.
SMPL, STAR and imGHUM approach all show improvements over their previous generation models. SMPL has a higher level of detail and easy integration in production pipelines compared to SCAP, the STAR model, on the other hand, integrates another improvement over SMPL by account- ing for body-mass index when estimating a pose, leading to more realistic replications. The imGHUM approach sets a completely new state-of-the-art by using a novel approach for making the estimations that are more robust to occlusion, can replicate much higher levels of detail than all previous approaches and can also generalize to inclusive body shapes. The parametric imGHUM model can be used for various contexts including fashion, computer games, avatar generation, imGHUM is the most detailed model out of all the model- based surveyed publications.
Model-Free Real Time Single-Camera
A single-camera real-time mesh estimation is a feat in itself and naturally deserves lower expectations of the overall quality due to the difficulty of the task. The Monocular Volumetric Rendering approach in itself does not model a full mesh but rather depicts an illusion from a certain camera perspective, the results are fairly low resolution with distortion artifacts around hands, feet, face. Although it is still able to replicate a reasonably detailed pose with recognisable facial features. The framework is made accessible due to only requiring consumer- grade single camera as input to the algorithm thus can be used for rapid prototyping. This solution could be useful for hobbyists, teleconferencing, education.
Model-Free Real Time Multi-Camera
While Function4D and Neural Human FVV are both in the same category, the Function4D framework uses an additional depth channel as input information to its algorithm. This additional level of detail allows the framework to save time on depth estimation and hence produces the estimations in a higher FPS. The Function4D output is less noisy when compared to Monocular Volumetric Rendering although this is expected because it uses more cameras as input. Nevertheless, it still produces detailed results with minimal artifacts in high-frequency components and renders recognizable facial features. The RGB-D camera cluster requirement makes this approach less accessible and more oriented towards pro- fessional productions or lab environments. The higher FPS could aid contexts of professional broadcasting, education, teleconferencing, or other contexts in which high resolution- low artifact output is not critical.
The Neural Human FFV on the other hand has higher levels of texture detail and can be more accessible by amature studios or labs, due to requiring only an RGB camera cluster. The decreased FPS makes this solution less optimal for highly dynamic contexts, but the increased texture resolution could benefit online showcases of fashion events, topology awareness can be useful for product showcases or streamed teleconferencing.
Model-Free Offline Single-View
The two publications of PIFuHD and Transformer Recon- struction are also two distinct frameworks with different use cases. PIFuHD is good at replicating a full mesh with fine-level of detail high-frequency components. This solution makes custom model generation for virtual environments incredibly accessible. Indie game studios can integrate this framework in a production pipeline to generate custom models, texture them, possibly fine-tune them by hand and afterwards rig them with other automated tools [38]. This framework can prove to be suitable for avatar generation, or any kind of virtual environment, simulation or computer game contexts where custom, detailed human meshes are required. The Transformer Reconstruction approach is not topology- aware, cannot produce high-resolution components but com- pletely deals with reconstructing a pose and body shape. Although due to the novel approach of estimation, the output is robust against self-occlusion. This can prove to be useful in situations where a model needs to be retrieved from noisy or less-than-ideal input. The output can still be used for gener- ating avatars or computer games although additional manual steps will be required to add individualized clothing or facial features. The model also generalizes well to other shapes, such as hands. If this framework could be extended to real- time hand-mesh rendering, this could benefit the immersion of virtual reality experiences, if a headset would be able to film the user’s hands and feed the RGB images as input to the algorithm, then virtual hands could be displayed in virtual reality thus increasing the immersion of the experiencing.
Conclusions
The 3D human mesh and pose reconstruction research field is divided into three separate research branches with their own unique sets of problems and advantages. From the reviewed literature, it is visible that all frameworks leverage a data- driven approach for solving the problem. So far none of the solutions provides the ultimate technological holy grail that is the quickest to render, has the highest level of pose, body and high-frequency detail estimation has the most detailed textures and least amount of artifacts. Therefore the consumers of this technology should be aware of the context and their own individual requirements in order to choose the most optimum solution for reconstructing humans as 3D meshes. This is identified as currently an active research field with the pace of improvements is increasing over years. The paper does not explicitly survey following relevant works [7, 8, 9, 10, 11, 12, 13, 14, 40, 17, 25] but rather acknowledges them as relevant literature that could provide an even deeper understanding of the current state-of-the-art.
References
[1] Ce Zheng et al. Deep Learning-Based Human Pose Esti- mation: A Survey. 2020. arXiv: 2012.13392 [cs.CV].
[2] Dragomir Anguelov et al. “Scape: shape completion and animation of people”. In: ACM SIGGRAPH 2005 Papers. 2005, pp. 408–416.
[3] Matthew Loper et al. “SMPL: A Skinned Multi-Person Linear Model”. In: ACM Trans. Graphics (Proc. SIG- GRAPH Asia) 34.6 (Oct. 2015), 248:1–248:16.
[4] Ahmed A A Osman, Timo Bolkart, and Michael J. Black. “STAR: A Sparse Trained Articulated Human Body Regressor”. In: European Conference on Com- puter Vision (ECCV). 2020, pp. 598–613. URL: https://star.is.tue.mpg.de.
[5] Hongyi Xu et al. “GHUM & GHUML: Generative 3D Human Shape and Articulated Pose Models”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020, pp. 6184–6193.
[6] Thiemo Alldieck, Hongyi Xu, and Cristian Smin- chisescu. “imGHUM: Implicit Generative Models of 3D Human Shape and Articulated Pose”. In: CoRR abs/2108.10842 (2021). arXiv: 2108.10842. URL: https://arxiv.org/abs/2108.10842.
[7] Sida Peng et al. “Neural Body: Implicit Neural Repre- sentations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans”. In: CVPR. 2021.
[8] Angjoo Kanazawa et al. “End-to-end Recovery of Hu- man Shape and Pose”. In: Computer Vision and Pattern Regognition (CVPR). 2018.
[9] Nikos Kolotouros, Georgios Pavlakos, and Kostas Dani- ilidis. “Convolutional Mesh Regression for Single- Image Human Shape Reconstruction”. In: CVPR. 2019.
[10] Yuanlu Xu, Song Zhu, and Tony Tung. “DenseRaC: Joint 3D Pose and Shape Estimation by Dense Render- and-Compare”. In: Oct. 2019, pp. 7759–7769. DOI: 10. 1109/ICCV.2019.00785.
[11] Sizhuo Zhang and Nanfeng Xiao. “Detailed 3D Hu- man Body Reconstruction From a Single Image Based on Mesh Deformation”. In: IEEE Access 9 (2021), pp. 8595–8603. DOI: 10.1109/ACCESS.2021.3049548.
[12] Zerong Zheng et al. “DeepHuman: 3D Human Recon- struction From a Single Image”. In: The IEEE Inter- national Conference on Computer Vision (ICCV). Oct.
[13] Enric Corona et al. “SMPLicit: Topology-aware Gener- ative Model for Clothed People”. In: CVPR. 2021.
[14] Taosha Fan et al. “Revitalizing Optimization for 3D Hu- man Pose and Shape Estimation: A Sparse Constrained Formulation”. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision (2021).
[15] Zhi-Quan Cheng et al. “Parametric modeling of 3D hu- man body shape—A survey”. In: Computers Graphics 71 (2018), pp. 88–100. ISSN: 0097-8493. DOI: https : //doi.org/10.1016/j.cag.2017.11.008. URL: https://www.sciencedirect.com/science/article/pii/S0097849317301929.
[16] Shunsuke Saito et al. “PIFuHD: Multi-Level Pixel- Aligned Implicit Function for High-Resolution 3D Hu- man Digitization”. In: CVPR. 2020.
[17] Tong He et al. “Geo-PIFu: Geometry and Pixel Aligned Implicit Functions for Single-view Human Reconstruc- tion”. In: Conference on Neural Information Processing Systems (NeurIPS). 2020.
[18] Kathleen M Robinette et al. Civilian american and european surface anthropometry resource (caesar), final report. volume 1. summary. Tech. rep. Sytronics Inc Dayton Oh, 2002.
[19] David Hirshberg et al. “Coregistration: Simultaneous Alignment and Modeling of Articulated 3D Shape”. In: vol. 7577. Oct. 2012, pp. 242–255. DOI: 10.1007/978- 3-642-33783-3 18.
[20] Matthew Tancik et al. “Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains”. In: NeurIPS (2020).
[21] Ruilong Li et al. “Monocular Real-Time Volumetric Performance Capture”. In: European Conference on Computer Vision. Springer. 2020, pp. 49–67.
[22] Wataru Kawai, Yusuke Mukuta, and Tatsuya Harada. “Real-Time Mesh Extraction from Implicit Functions via Direct Reconstruction of Decision Boundary”. In: 2021 IEEE International Conference on Robotics and Automation (ICRA). 2021, pp. 12875–12881. DOI: 10. 1109/ICRA48506.2021.9560749.
[23] Tao Yu et al. “Function4D: Real-Time Human Volu- metric Capture From Very Sparse Consumer RGBD Sensors”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 2021, pp. 5746–5756.
[24] Xin Suo et al. “NeuralHumanFVV: Real-Time Neural Volumetric Human Performance Rendering using RGB Cameras”. In: June 2021, pp. 6222–6233. DOI: 10.1109/ CVPR46437.2021.00616.
[25] Zeng Huang et al. “ARCH: Animatable Reconstruction of Clothed Humans”. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020, pp. 3090–3099. DOI: 10.1109/CVPR42600.2020.
[26] Zeng Huang et al. “Deep Volumetric Video From Very Sparse Multi-View Performance Capture”. In: European Conference on Computer Vision (ECCV). 2018.
[27] Kevin Lin, Lijuan Wang, and Zicheng Liu. “End-to-End Human Pose and Mesh Reconstruction with Transform- ers”. In: CVPR. 2021.
[28] Shunsuke Saito et al. “PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digi- tization”. In: The IEEE International Conference on Computer Vision (ICCV). Oct. 2019.
[29] Yebin Liu et al. “Markerless motion capture of interact- ing characters using multi-view image segmentation”. In: CVPR 2011. 2011, pp. 1249–1256. DOI: 10.1109/ CVPR.2011.5995424.
[30] Tobias Werner and Dominik Henrich. “Efficient and precise multi-camera reconstruction”. In: Proceedings of the International Conference on Distributed Smart Cameras. 2014, pp. 1–6.
[31] KMG Cheung, Simon Baker, and Takeo Kanade. “Shape-from-silhouette of articulated objects and its use for human body kinematics estimation and motion capture”. In: 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings. Vol. 1. IEEE. 2003, pp. I–I.
[32] RenderPeople 3D People. https://renderpeople.com/3d- people/. Accessed: 2022-01-02.
[33] Ashish Vaswani et al. “Attention is all you need”. In: Advances in neural information processing systems. 2017, pp. 5998–6008.
[34] Jiang Wang et al. “Mining actionlet ensemble for action recognition with depth cameras”. In: 2012 IEEE Con- ference on Computer Vision and Pattern Recognition. 2012, pp. 1290–1297. DOI: 10 . 1109 / CVPR . 2012 .
[35] SizeUSA. https://www.tc2.com/size-usa.html. Accessed: 2022-01-06.
[36] Human3.6M. http://vision.imar.ro/human3.6m/ description.php. Accessed: 2022-01-06.
[37] CMU Mocap Dataset. http://mocap.cs.cmu.edu/. Accessed: 2022-01-06.
[38] Mixamo. https://www.mixamo.com/. Accessed: 2022- 01-06.
[39] Human 3D Body Model Dataset for Research. https : //web.twindom.com/human-3d-body-scan-dataset-for- research-from-3d-scans/. Accessed: 2022-01-06.
[40] George Fahim, Khalid Amin, and Sameh Zarif. “Single- View 3D Reconstruction: A Survey of Deep Learning Methods”. In: Computers Graphics 94 (Jan. 2021). DOI: 10.1016/j.cag.2020.12.004