
Comparative Study of NLP Adversarial Attack Frameworks Against a BERT-Based Textual Entailment Model
Relevant GitHub Repos:
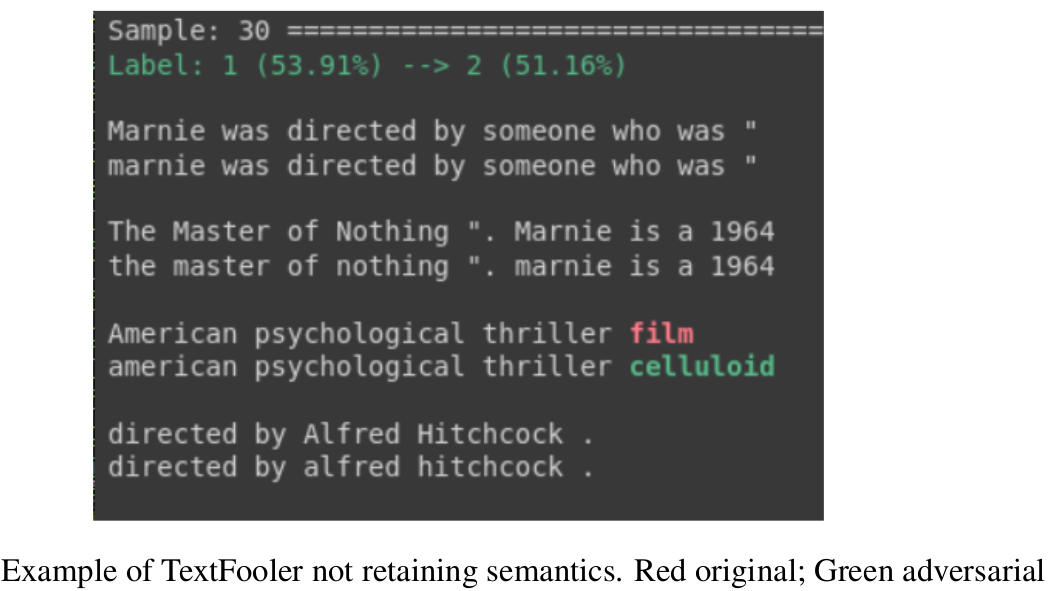
Deep learning models can provide incredible results although when impaired through adversarial attacks, they can quickly crumble. This work shows the effects of two fundamentally different adversarial attack frameworks namely Universal Adversarial Triggers(Wallace et al., 1) and TextFooler(Jin et al., 2019), and their effects on DestilBERT model fine-tuned on Fever dataset for sequence classification problem. The result shows that both attacks are efficient and can make the model virtually unusable as the predictions are heavily skewed. The results do not quite correlate with previous research done within the field as they do not give much insight into how the model works, although this is attributed to potential flaws in the methodology when obtaining the results. Overall this work demonstrates the motivation for adversarial training to defend against adversarial attacks and shows also that both attack frameworks themselves can be further improved.